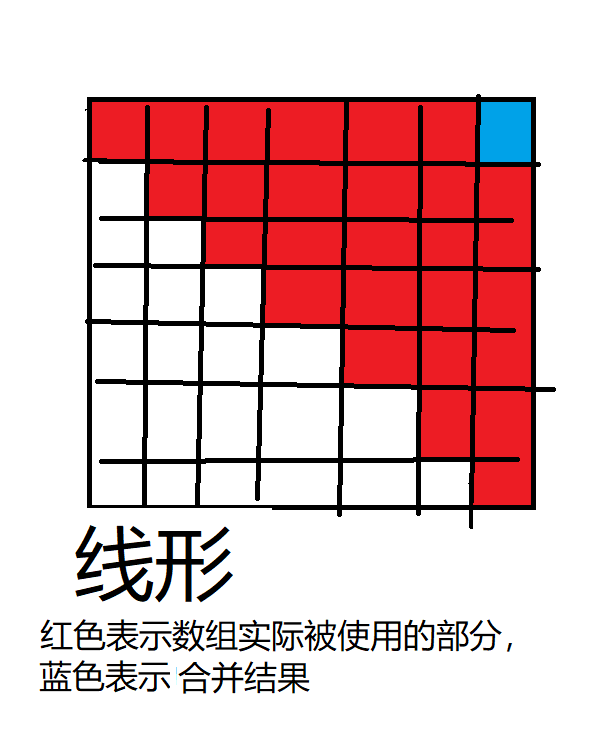
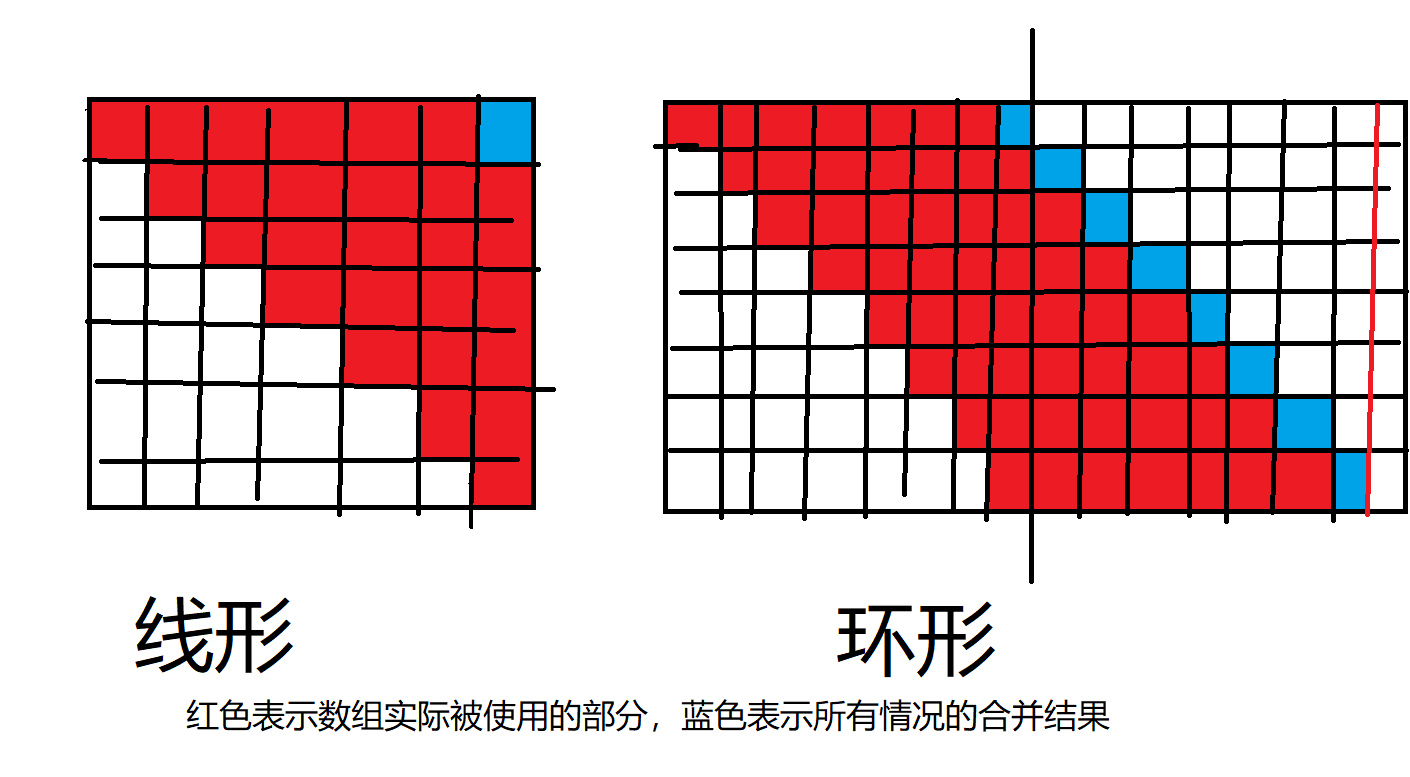
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| class ICC_UnknowColorName(Exception):
pass
class ICC_UnknowMixType(Exception):
pass
class ColorOrder:
BaseOrderLength_Normal = 16
ErrorText_ICC_UnknowColorName = 'Exist color name not in ColorOrder.ColorMap, can not identify what color the name means. Or you need to use an iteratable object to iteratable object all color names'
ErrorText_ICC_UnknowMixType = 'Can not identify mixtype'
ColorMap = {
'Gray' : 'Gray'
,'Red' : 'Red'
,'Redpurple' : 'RedPurple'
,'Purplered' : 'RedPurple'
,'Purple' : 'Purple'
,'Purpleblue' : 'PurpleBlue'
,'Bluepurple' : 'PurpleBlue'
,'Blue' : 'Blue'
,'Bluecyan' : 'BlueCyan'
,'Cyanblue' : 'BlueCyan'
,'Cyan' : 'Cyan'
,'Cyangreen' : 'CyanGreen'
,'Greencyan' : 'CyanGreen'
,'Green' : 'Green'
,'Greenyellow' : 'GreenYellow'
,'Yellowgreen' : 'GreenYellow'
,'Yellow' : 'Yellow'
,'Yelloworange': 'YellowOrange'
,'Orangeyellow': 'YellowOrange'
,'Orange' : 'Orange'
,'Orangered' : 'OrangeRed'
,'Redorange' : 'OrangeRed'
}
BaseColorOrder = {
'Gray' : ['#ffffff','#272727','#3C3C3C','#4F4F4F','#5B5B5B','#6C6C6C','#7B7B7B','#8E8E8E','#9D9D9D','#ADADAD','#BEBEBE','#d0d0d0','#E0E0E0','#F0F0F0','#FCFCFC','#FFFFFF']
,'Red' : ['#2F0000','#4D0000','#600000','#750000','#930000','#AE0000','#CE0000','#EA0000','#FF0000','#FF2D2D','#FF5151','#ff7575','#FF9797','#FFB5B5','#FFD2D2','#FFECEC']
,'RedPurple' : ['#600030','#820041','#9F0050','#BF0060','#D9006C','#F00078','#FF0080','#FF359A','#FF60AF','#FF79BC','#FF95CA','#ffaad5','#FFC1E0','#FFD9EC','#FFECF5','#FFF7FB']
,'Purple' : ['#460046','#5E005E','#750075','#930093','#AE00AE','#D200D2','#E800E8','#FF00FF','#FF44FF','#FF77FF','#FF8EFF','#ffa6ff','#FFBFFF','#FFD0FF','#FFE6FF','#FFF7FF']
,'PurpleBlue' : ['#28004D','#3A006F','#4B0091','#5B00AE','#6F00D2','#8600FF','#921AFF','#9F35FF','#B15BFF','#BE77FF','#CA8EFF','#d3a4ff','#DCB5FF','#E6CAFF','#F1E1FF','#FAF4FF']
,'Blue' : ['#000079','#000093','#0000C6','#0000C6','#0000E3','#2828FF','#4A4AFF','#6A6AFF','#7D7DFF','#9393FF','#AAAAFF','#B9B9FF','#CECEFF','#DDDDFF','#ECECFF','#FBFBFF']
,'BlueCyan' : ['#000079','#003D79','#004B97','#005AB5','#0066CC','#0072E3','#0080FF','#2894FF','#46A3FF','#66B3FF','#84C1FF','#97CBFF','#ACD6FF','#C4E1FF','#D2E9FF','#ECF5FF']
,'Cyan' : ['#003E3E','#005757','#007979','#009393','#00AEAE','#00CACA','#00E3E3','#00FFFF','#4DFFFF','#80FFFF','#A6FFFF','#BBFFFF','#CAFFFF','#D9FFFF','#ECFFFF','#FDFFFF']
,'CyanGreen' : ['#006030','#01814A','#019858','#01B468','#02C874','#02DF82','#02F78E','#1AFD9C','#4EFEB3','#7AFEC6','#96FED1','#ADFEDC','#C1FFE4','#D7FFEE','#E8FFF5','#FBFFFD']
,'Green' : ['#006000','#007500','#009100','#00A600','#00BB00','#00DB00','#00EC00','#28FF28','#53FF53','#79FF79','#93FF93','#A6FFA6','#BBFFBB','#CEFFCE','#DFFFDF','#F0FFF0']
,'GreenYellow' : ['#467500','#548C00','#64A600','#73BF00','#82D900','#8CEA00','#9AFF02','#A8FF24','#B7FF4A','#C2FF68','#CCFF80','#D3FF93','#DEFFAC','#E8FFC4','#EFFFD7','#F5FFE8']
,'Yellow' : ['#424200','#5B5B00','#737300','#8C8C00','#A6A600','#C4C400','#E1E100','#F9F900','#FFFF37','#FFFF6F','#FFFF93','#FFFFAA','#FFFFB9','#FFFFCE','#FFFFDF','#FFFFF4']
,'YellowOrange': ['#5B4B00','#796400','#977C00','#AE8F00','#C6A300','#D9B300','#EAC100','#FFD306','#FFDC35','#FFE153','#FFE66F','#FFED97','#FFF0AC','#FFF4C1','#FFF8D7','#FFFCEC']
,'Orange' : ['#844200','#9F5000','#BB5E00','#D26900','#EA7500','#FF8000','#FF9224','#FFA042','#FFAF60','#FFBB77','#FFC78E','#FFD1A4','#FFDCB9','#FFE4CA','#FFEEDD','#FFFAF4']
,'OrangeRed' : ['#642100','#842B00','#A23400','#BB3D00','#D94600','#F75000','#FF5809','#FF8040','#FF8F59','#FF9D6F','#FFAD86','#FFBD9D','#FFCBB3','#FFDAC8','#FFE6D9','#FFF3EE']
}
def __init__(self, colornames, mixtype = 'Connect'):
colornames = [i.capitalize() for i in colornames]
mixtype = mixtype.capitalize()
for each in colornames:
if each not in ColorOrder.ColorMap:
raise ICC_UnknowColorName(ColorOrder.ErrorText_ICC_UnknowColorName)
self.__order = []
if mixtype == 'Connect':
for eachname in colornames:
self.__order.extend(ColorOrder.BaseColorOrder[ColorOrder.ColorMap[eachname]])
elif mixtype == 'Cross':
lst = []
for eachname in colornames:
lst.append(ColorOrder.BaseColorOrder[ColorOrder.ColorMap[eachname]])
for i in range(ColorOrder.BaseOrderLength_Normal):
for each in lst:
self.__order.append(each[i])
else:
raise ICC_UnknowMixType(ColorOrder.ErrorText_ICC_UnknowMixType)
self.__baseOrderNumber = len(colornames)
self.__length = self.__baseOrderNumber * ColorOrder.BaseOrderLength_Normal
def getBaseOrderNumber(self):
return self.__baseOrderNumber
def getLength(self):
return self.__length
def getOrder(self):
return self.__order.copy()
def getLeft(self, muti_section = False):
if muti_section == False:
lst = self.__order[ : 4 * self.__baseOrderNumber ]
else:
lst = []
for i in range(self.__baseOrderNumber):
pos = i * ColorOrder.BaseOrderLength_Normal
lst.extend(self.__order[ pos : pos + 4])
return lst
def getRight(self, muti_section = False):
if muti_section == False:
lst = self.__order[ -4 * self.__baseOrderNumber : ]
else:
lst = []
for i in range(1,self.__baseOrderNumber+1):
pos = i * ColorOrder.BaseOrderLength_Normal
lst.extend(self.__order[ pos - 4 : pos])
return lst
def getMiddle(self, muti_section = False):
if muti_section == False:
lst = self.__order[ 4 * self.__baseOrderNumber : 12 * self.__baseOrderNumber ]
else:
lst = []
for i in range(self.__baseOrderNumber):
pos = i * ColorOrder.BaseOrderLength_Normal
lst.extend(self.__order[ pos + 4 : pos + 12])
return lst
def mix(self, co, mixtype = 'Connect'):
mixtype = mixtype.capitalize()
if mixtype == 'Connect':
self.__order.extend(co.__order)
elif mixtype == 'Cross':
lst = []
idx1 = 0
idx2 = 0
for i in range(ColorOrder.BaseOrderLength_Normal):
for j in range(self.__baseOrderNumber):
lst.append(self.__order[idx1])
idx1 += 1
for j in range(co.__baseOrderNumber):
lst.append(co.__order[idx2])
idx2 += 1
self.__order = lst
self.__length += co.__length
self.__baseOrderNumber += co.__baseOrderNumber
|