说明 - 2022-05-05
本篇博客为本人原创, 原发布于CSDN, 在搭建个人博客后使用爬虫批量爬取并挂到个人博客, 出于一些技术原因博客未能完全还原到初始版本(而且我懒得修改), 在观看体验上会有一些瑕疵 ,若有需求会发布重制版总结性新博客。发布时间统一定为1111年11月11日。钦此。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
导入数据
# 从excel表导入数据
df_t = pd.read_excel(r’D:\EdgeDownloadPlace\3dd40612152202ee8440f82a3d277008\train.xlsx’)
# 删除uid列
df_t = df_t.drop(columns='uid')
# 把数据中的'?'换成每一列的众数
for col in df_t.columns:
idx = df_t[col].value_counts().index
df_t[col][df_t[col] == '?'] = idx[0] if idx[0] != '?' else idx[1]
# 把pandas.DataFrame数据转化为numpy.darray数据 元素类型为np.float32
arr_t = df_t.values.astype(np.float32)
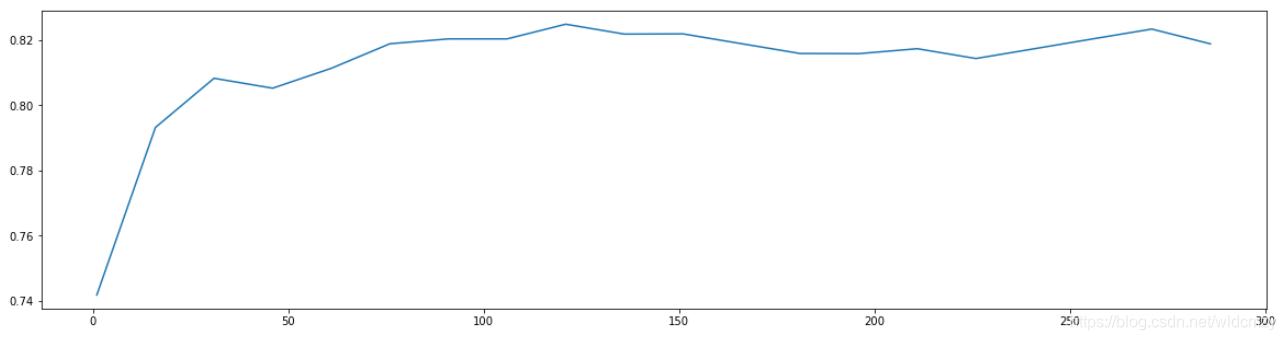
交叉验证找分数最高的n_estimators
score_tt = []
for i in range(0,300,15):
rfc = RandomForestClassifier(n_estimators = i+1
,n_jobs = -1
,random_state = 156535
)
score = cross_val_score(rfc, arr_t[:,:-1],arr_t[:,-1],cv=10).mean()
score_tt.append(score)
peak = [max(score_tt), score_tt.index(max(score_tt))*15+1]
plt.figure(figsize = [20,5])
plt.plot(range(1,301,15),score_tt)
plt.show()
peak
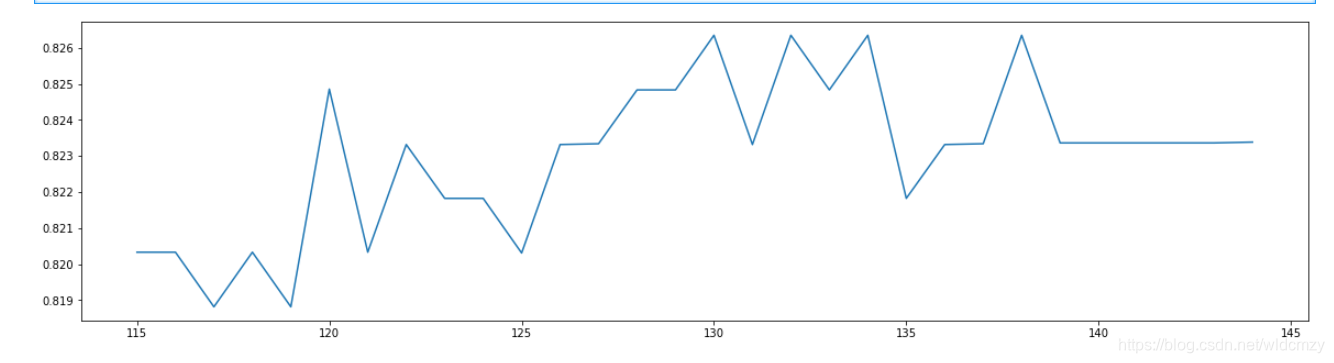
score_tt = []
for i in range(peak[1]-15,peak[1]+15):
rfc = RandomForestClassifier(n_estimators = i+1
,n_jobs = -1
,random_state = 156535)
score = cross_val_score(rfc, arr_t[:,:-1],arr_t[:,-1],cv=10).mean()
score_tt.append(score)
peak = [max(score_tt), ([*range(peak[1]-15,peak[1]+15)][score_tt.index(max(score_tt))])]
plt.figure(figsize = [20,5])
plt.plot(range(peak[1]-15,peak[1]+15),score_tt)
plt.show()
peak
n_peak = peak[1]
网格化搜索找最大深度
param_grid = {‘max_depth’ : np.arange(1,14)}
rfc = rfc = RandomForestClassifier(n_estimators = n_peak
,random_state = 156535
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(arr_t[:,:-1],arr_t[:,-1])
#GS.best_params_ #返回最佳参数
#GS.best_score_ #返回最佳参数对应的准确率
[GS.best_score_, GS.best_params_]
depth_peak=GS.best_params_[‘max_depth’]
同理min_samples_split
param_grid = {‘min_samples_split’ : np.arange(2,30)}
rfc = rfc = RandomForestClassifier(n_estimators = n_peak
,random_state = 156535
,max_depth = depth_peak
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(arr_t[:,:-1],arr_t[:,-1])
#GS.best_params_ #返回最佳参数
#GS.best_score_ #返回最佳参数对应的准确率
[GS.best_score_, GS.best_params_]
同理 criterion
param_grid = {‘criterion’ : [‘gini’,‘entropy’]}
rfc = rfc = RandomForestClassifier(n_estimators = n_peak
,random_state = 156535
,max_depth = depth_peak
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(arr_t[:,:-1],arr_t[:,-1])
#GS.best_params_ #返回最佳参数
#GS.best_score_ #返回最佳参数对应的准确率
[GS.best_score_, GS.best_params_]
网格化搜索n_estimators
param_grid = {‘n_estimators’ : np.arange(1,300,15)}
rfc = RandomForestClassifier( random_state = 156535
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(arr_t[:,:-1],arr_t[:,-1])
#GS.best_params_ #返回最佳参数
#GS.best_score_ #返回最佳参数对应的准确率
[GS.best_score_, GS.best_params_]